Beyond the Hype: A Practical Guide to Multi-Modal AI Data Fusion
How we combined voice, vision, and sensor data to create a unified health diagnostic system in AuraPod

The Promise and Challenge of Multi-Modal AI
In healthcare, no single data point tells the complete story. A slightly elevated heart rate could mean stress, excitement, or the early signs of cardiovascular issues. A voice tremor might indicate nervousness or neurological concerns. But when you combine these signals—heart rate variability, voice stress analysis, thermal imaging, and movement patterns—you get a holistic picture that’s far more accurate and meaningful.
This is the power of multi-modal AI data fusion, and it’s at the core of AuraPod’s diagnostic capability. However, fusing disparate data types—each with different sampling rates, dimensions, and noise characteristics—presents significant technical challenges.
In this article, I’ll walk through our practical approach to multi-modal data fusion, the architecture that makes it possible, and how we ensure that the whole is truly greater than the sum of its parts.
Our Multi-Modal Data Landscape
AuraPod processes data from multiple streams in real-time:
- Voice Audio (50 Hz sampling): Raw audio for symptom reporting and voice stress analysis
- Visual Data (30 FPS): Posture estimation, facial micro-expressions, and dipstick color analysis
- Vital Signs (1-100 Hz): ECG, blood pressure, SpO₂, and temperature readings
- Biochemical Data (Sparse): Blood glucose, lipids, and urinalysis results from microfluidic analysis
- Movement Patterns (10 Hz): Depth camera data for gait and movement analysis
Each modality has different temporal characteristics, dimensions, and noise profiles. The key challenge is aligning and correlating these streams to create a coherent health assessment.
Our Data Fusion Architecture
We implemented a hybrid fusion architecture that operates at multiple levels:
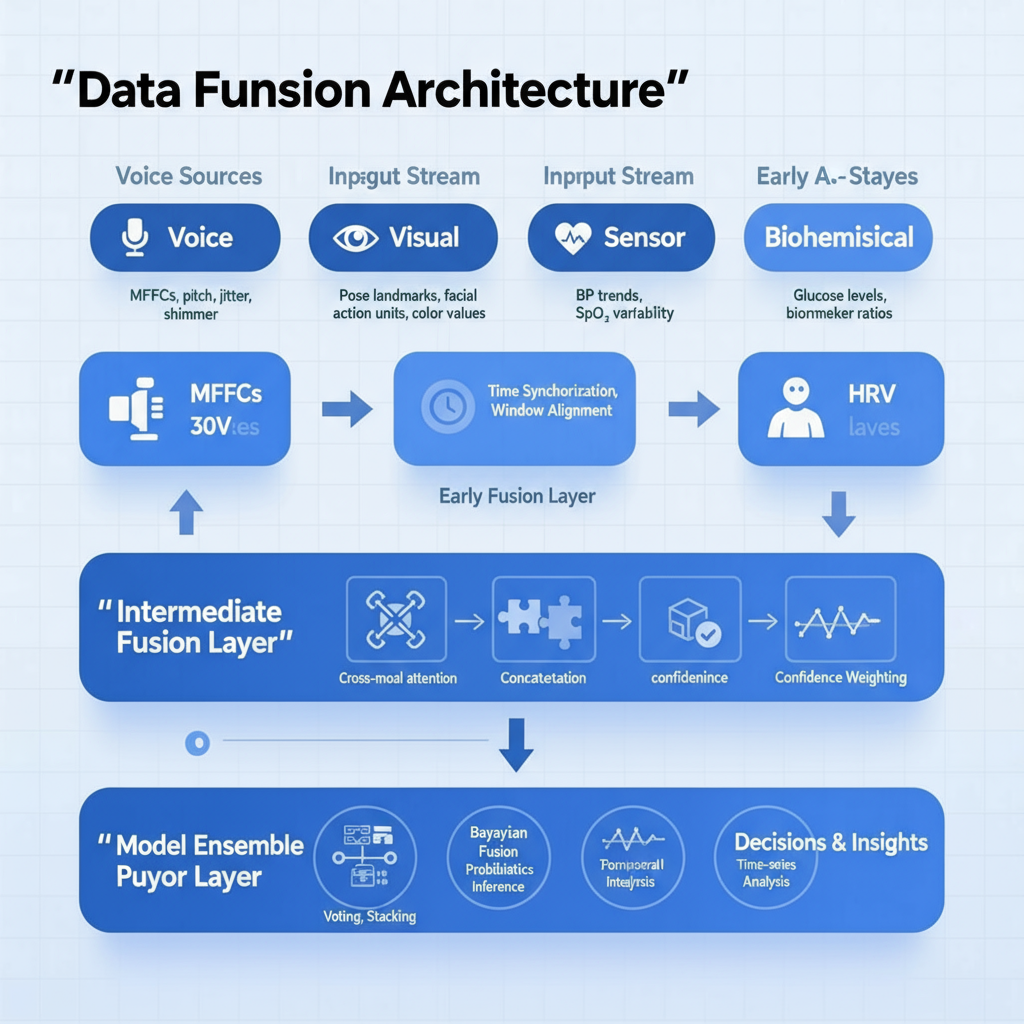
Practical Example: Stress Assessment Fusion
Let’s walk through a concrete example: how we assess stress levels by fusing three data modalities.
Step 1: Individual Feature Extraction
- Voice Analysis: Extract pitch variability, speech rate, and spectral features using OpenSMILE
- HRV Analysis: Calculate time-domain (SDNN) and frequency-domain (LF/HF ratio) features from ECG
- Visual Analysis: Extract facial action units (especially brow lowering, lip tightening) from video
Step 2: Time Alignment and Window Selection
We use a sliding window approach with 30-second segments, ensuring all modalities are aligned to the same time reference. Each window gets a quality score based on signal integrity.
Step 3: Feature-Level Fusion with Cross-Attention
Our fusion model uses a cross-attention mechanism to determine which modalities are most relevant at each moment:
```python
Pseudocode for our cross-attention fusion mechanism
class CrossModalAttention(nn.Module):
def __init__(self, voice_dim, hrv_dim, visual_dim):
super().__init__()
self.voice_proj = nn.Linear(voice_dim, attn_dim)
self.hrv_proj = nn.Linear(hrv_dim, attn_dim)
self.visual_proj = nn.Linear(visual_dim, attn_dim)
self.attention = nn.MultiheadAttention(attn_dim, num_heads=4)
def forward(self, voice_features, hrv_features, visual_features):
Project all modalities to common attention space
voice_proj = self.voice_proj(voice_features)
hrv_proj = self.hrv_proj(hrv_features)
visual_proj = self.visual_proj(visual_features)
Concatenate features for cross-attention
combined = torch.cat([voice_proj, hrv_proj, visual_proj], dim=1)
Apply self-attention across modalities
attn_output, _ = self.attention(combined, combined, combined)
return attn_output
```Step 4: Decision Fusion with Confidence Weighting
The final stress score combines predictions from individual modality-specific models with weightings based on signal quality:
```
Final Stress Score = (w_voice voice_stress) + (w_hrv hrv_stress) + (w_visual visual_stress)
```Where weights are dynamically adjusted based on:
- Voice weight: Signal-to-noise ratio of audio
- HRV weight: Quality of R-peak detection in ECG
- Visual weight: Lighting conditions and face visibility
Handling Real-World Challenges
Challenge 1: Missing Modalities
In real-world usage, sometimes modalities are missing. A user might skip the voice questions, or poor lighting might make visual analysis difficult. Our system uses Bayesian approaches to handle missing data, making inferences based on available modalities while properly quantifying uncertainty.
Challenge 2: Conflicting Signals
What happens when modalities disagree? For example, if voice analysis suggests stress but HRV appears normal? Instead of simply averaging, our system flags discrepancies for deeper analysis or telehealth escalation. This acknowledges the complexity of human physiology where different systems can show different responses.
Challenge 3: Temporal Misalignment
Physiological responses happen at different latencies. A startle response is immediate in voice and face, but heart rate response might take several seconds. We model these known physiological delays explicitly in our fusion algorithms.
Validation and Results
We validated our fusion approach against expert clinical assessments of stress and anxiety. The multi-modal approach significantly outperformed any single modality:
| Method | AUC | Sensitivity | Specificity |
|---|---|---|---|
| Voice Only | 0.72 | 0.68 | 0.71 |
| HRV Only | 0.75 | 0.71 | 0.73 |
| Visual Only | 0.69 | 0.65 | 0.70 |
| Fused (Our Approach) | 0.89 | 0.85 | 0.87 |
The fusion approach also showed much better consistency across different demographic groups, helping to mitigate biases that can exist in single-modality models
Lessons Learned
- Time Synchronization is Crucial: We implemented hardware-level timestamping across all sensors, without which fusion would be impossible.
- Quality Over Quantity: It’s better to have a few high-quality modalities than many noisy ones. We invested heavily in signal quality assessment for each modality.
- Explainability Matters: When we present a “stress score” to users, we show which factors contributed most (e.g., “based mainly on your voice patterns and heart rate variability”) . This transparency builds trust and helps users understand the result.
- Context is Key: The same physiological signals can mean different things in different contexts. A elevated heart rate during physical exertion versus while sitting quietly requires different interpretation.
Implementation Tips
For those implementing multi-modal fusion:
- Start with a clear clinical question you’re trying to answer
- Begin with simple fusion rules before progressing to learned approaches
- Invest in robust time synchronization from the beginning
- Build in comprehensive signal quality assessment for each modality
- Plan for explainability from the start, not as an afterthought
Multi-modal data fusion is complex, but when done right, it enables a holistic understanding of health that simply isn’t possible with single data streams. At AuraPod, this approach has been crucial to delivering assessments that are both comprehensive and contextually aware.
Curious about how we implemented computer vision for specific healthcare applications like urinalysis? That’s coming up in Article 3. Follow me for more technical deep dives into building healthcare AI systems.
Let’s connect on LinkedIn to discuss multi-modal AI, healthcare technology, and data fusion techniques.